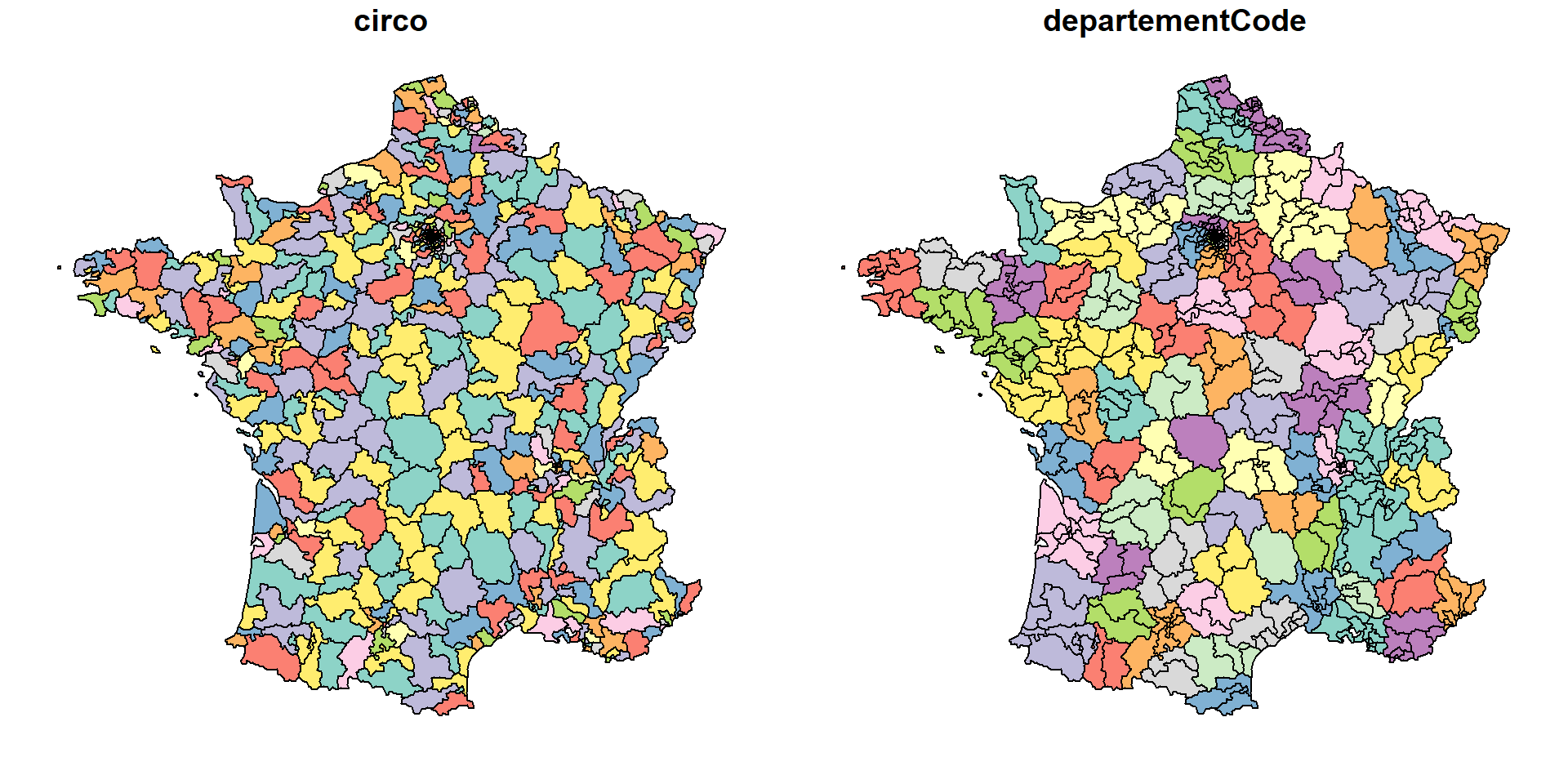
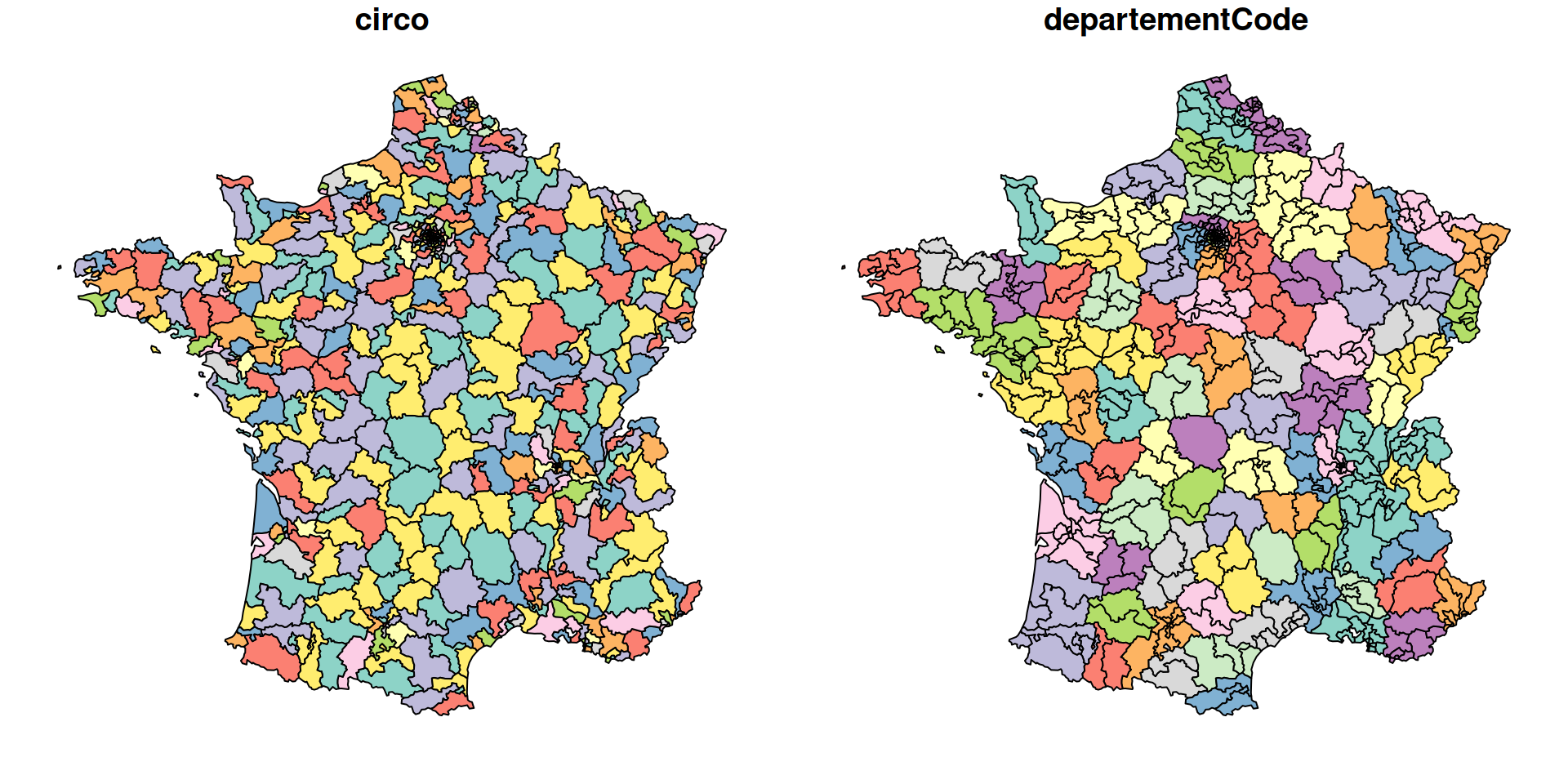
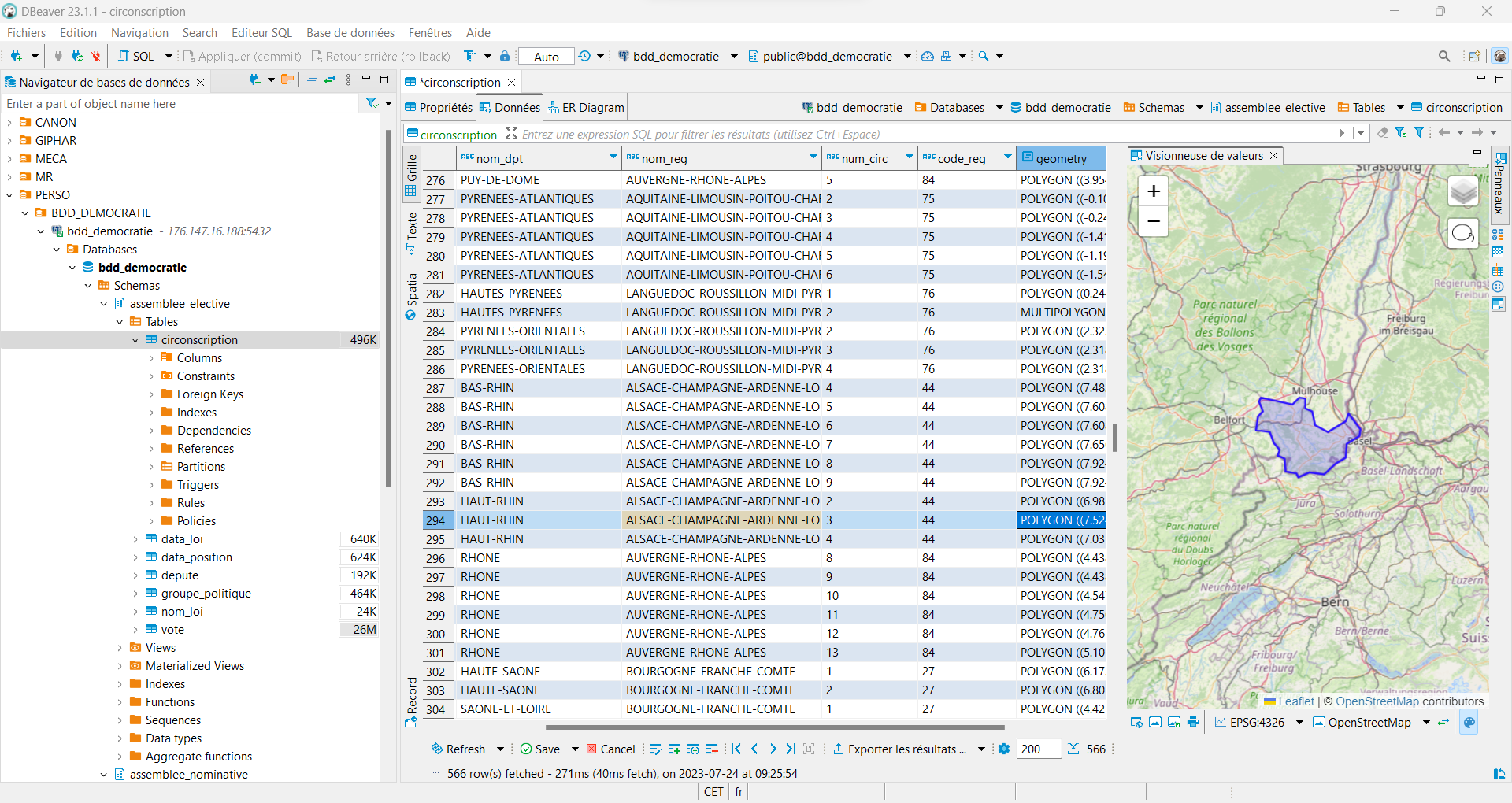
"SELECT departementnom, geometry as circonscription, ST_SetSRID(ST_MakePoint(7.179495 , 47.9343092),4326) as point, ST_Contains(geometry,ST_SetSRID(ST_MakePoint(7.179495 , 47.9343092),4326)) as point_in_circo FROM assemblee_elective.circonscription_2 WHERE departementnom in ('BAS-RHIN','HAUT-RHIN');"
[('BAS-RHIN', '0106000020E6100000010000000103000000010000000800000021CA17B490C01E407558E1968F4C4840E5B7E864A9D51E4055DB4DF04D4D4840CE531D7233EC1E40035DFB027A5348404BC972124A0F1F408BE07F2BD953484097E5EB32FC571F40AA29C93A1C5148404CC11A67D3311F40FB20CB82894B484092B442DA18271F40FB668163A34B484021CA17B490C01E407558E1968F4C4840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('BAS-RHIN', '0106000020E6100000010000000103000000010000000A0000008A8F4FC8CEEB1E40B2F2CB608C46484029EACC3D24EC1E4009FD4CBD6E47484026FBE769C0F01E409DD9AED00749484092B442DA18271F40FB668163A34B48404CC11A67D3311F40FB20CB82894B484085ED27637C381F404DBB9866BA414840F5B9DA8AFD151F40912BF52C083F4840DEE522BE13D31E40EFA83121E64048403BE5D18DB0C81E401EFB592C454448408A8F4FC8CEEB1E40B2F2CB608C464840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('BAS-RHIN', '0106000020E610000001000000010300000001000000170000002A8BC22E8AEE1D40965B5A0D895348403FC571E0D5121E4076FA415DA45848409B3924B550521E40C1FEEBDCB45B48406D8C9DF0128C1E40386A85E97B594840378E588B4FC11E40B5DD04DF34554840CE531D7233EC1E40035DFB027A534840E5B7E864A9D51E4055DB4DF04D4D484021CA17B490C01E407558E1968F4C4840543A58FFE7D01E40A0C552245F47484029EACC3D24EC1E4009FD4CBD6E4748408A8F4FC8CEEB1E40B2F2CB608C4648403BE5D18DB0C81E401EFB592C45444840DEE522BE13D31E40EFA83121E6404840F5B9DA8AFD151F40912BF52C083F484077BD344580031F406CCEC133A1374840A8FFACF9F1C71E407B8670CCB2394840A94E07B29ECA1E404ACE893DB43D484041F33977BB6E1E4021ACC612D63C484018E945ED7E551E4025917D9065434840F0A5F0A0D9551E4055DE8E705A4A48409E7AA4C16D2D1E400D71AC8BDB4A4840D89AADBCE42F1E40BF620D17B94F48402A8BC22E8AEE1D40965B5A0D89534840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('BAS-RHIN', '0106000020E6100000010000000103000000010000001D00000041F33977BB6E1E4021ACC612D63C4840A94E07B29ECA1E404ACE893DB43D4840A8FFACF9F1C71E407B8670CCB239484077BD344580031F406CCEC133A1374840A5F3E15982EC1E4010AFEB17EC3048400EBBEF181EFB1E406CAF05BD372A4840FAEFC16B97C61E40A837A3E6AB26484071CADC7C23AA1E40730E9E094D1C48401AC05B2041911E40E5417A8A1C1A48400CCC0A45BA4F1E404E7B4ACE890F4840FB7953910A131E4096CD1C925A104840CAFCA36FD2141E404260E5D0221348406F2A52616CE11D40B2D5E594801448407A39ECBE63E81D4052431B800D1A4840309B00C3F2671D40A81DFE9AAC1F4840AF5C6F9BA9401D402975C93846204840B2DAFCBFEA181D40B265F9BA0C274840B98AC56F0ACB1C408194D8B5BD2748400AD9791B9BAD1C408F183DB7D02B484056D636C5E3D21C4026529ACDE32E484061C43E0114131D40BA13ECBFCE3148409082A7902B351D4024B726DD96364840624B8FA67A921D408D98D9E731364840E198654F02AB1D4066118AADA037484089F02F82C6EC1D4085B53176C23548409161156F64EE1D4018CC5F21733148406B0DA5F6222A1E4095B54DF1B83248409D4A06802A5E1E404303B16CE638484041F33977BB6E1E4021ACC612D63C4840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('BAS-RHIN', '0106000020E6100000010000000103000000010000001D00000041F33977BB6E1E4021ACC612D63C48409D4A06802A5E1E404303B16CE63848406B0DA5F6222A1E4095B54DF1B83248409161156F64EE1D4018CC5F217331484089F02F82C6EC1D4085B53176C2354840E198654F02AB1D4066118AADA0374840624B8FA67A921D408D98D9E7313648409082A7902B351D4024B726DD9636484061C43E0114131D40BA13ECBFCE31484056D636C5E3D21C4026529ACDE32E48400AD9791B9BAD1C408F183DB7D02B4840B5368DEDB5901C4077D7D9907F2A484081B1BE81C94D1C40B3075A81212D484087DEE2E13D671C40C289E8D7D62F4840029CDEC5FB611C4017D522A298364840200C3CF71E7E1C405EBEF561BD414840377172BF43511C402C7E5358A944484083A279008BAC1C40E34F5436AC4348404E0CC9C9C4DD1C406EBE11DDB3464840C136E2C96E061D4055F833BC594B4840925D6919A9371D40FF3EE3C2815448407B698A00A7771D40C8EE022505524840B8921D1B81981D40C3EFA65B765448402A8BC22E8AEE1D40965B5A0D89534840D89AADBCE42F1E40BF620D17B94F48409E7AA4C16D2D1E400D71AC8BDB4A4840F0A5F0A0D9551E4055DE8E705A4A484018E945ED7E551E4025917D906543484041F33977BB6E1E4021ACC612D63C4840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('BAS-RHIN', '0106000020E61000000100000001030000000100000025000000C7D79E5912A01E40B56B425A636C4840ED478AC8B07A1E40BE9F1A2FDD6A4840F1D58EE21C751E40DF88EE59D7664840AA9D616A4B9D1E40BAA0BE654E5D48406D8C9DF0128C1E40386A85E97B5948409B3924B550521E40C1FEEBDCB45B48403FC571E0D5121E4076FA415DA45848402A8BC22E8AEE1D40965B5A0D89534840B8921D1B81981D40C3EFA65B765448407B698A00A7771D40C8EE022505524840925D6919A9371D40FF3EE3C281544840BBD6DEA7AA101D40D68D7747C6544840874F3A91600A1D403485CE6BEC5848400168942EFD3B1D4051A04FE449624840A4C16D6DE1291D40320400C79E654840E083D72E6D981C405DA626C11B6C4840FD87F4DBD7811C402F14B01D8C664840B05758703F301C409B711AA20A694840D5CF9B8A54381C4062DC0DA2B56E48407731CD74AFF31B40B859BC581872484090F46915FDD11B4097546D37C17548408F334DD87EF21B40B2D826158D794840433D7D04FE201C40CF2F4AD05F7A48405AD5928E72201C40A3755435417E484041800C1D3B381C40C32B499EEB83484000AC8E1CE96C1C409180D1E5CD8548407A54FCDF11851C40715AF0A2AF804840C39E76F86BB21C4036E7E099D0804840B0C56E9F55D61C40DD990986737D48409E5C5320B3F31C407CF2B0506B7E484044A51133FB2C1D40BFB7E9CF7E7C4840E065868DB24E1D404AD1CABDC078484069705B5B78CE1D40CCB8A981E67B4840F96706F1810D1E40DBF97E6ABC7848408A027D224FF21D40B80375CAA37348402D27A1F485501E4047CCECF3186D4840C7D79E5912A01E40B56B425A636C4840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('BAS-RHIN', '0106000020E610000001000000010300000001000000210000004565C39ACAB21F40F75AD07B63584840B7973446EB781F404580D3BB785B4840433A3C84F1B31F40FEEF880AD56348409ED1562591DD1F40D87F9D9B366B484085D21742CECB1F4007793D98146F4840F8A41309A69A1F40E010AAD4EC7148400A12DBDD03541F40477364E59773484076374F75C8FD1E4060ADDA35216F4840C7D79E5912A01E40B56B425A636C48402D27A1F485501E4047CCECF3186D48408A027D224FF21D40B80375CAA3734840F96706F1810D1E40DBF97E6ABC78484074620FED63251E40641EF983817748408066101FD8511E4048348122167B4840D6C743DFDD5A1E40726A6798DA7E4840376DC669888A1E405036E50AEF864840B779E3A430AF1E40DFBF7971E28548409B9141EE22EC1E4087FC3383F8864840B58D3F51D9101F401B2C9CA4F985484078D503E621331F404FCAA48636884840B32781CD39781F40BD56427749844840E42CEC6987BF1F408D7E349C328748408CDAFD2AC0E71F40A83462669F834840E84B6F7F2E1A20409561DC0DA28148405247C7D5C82E204037A79201A07E4840A87004A914632040492EFF21FD7C4840F1B8A81611652040A5F3E159827A4840FC51D4997B4820406FF25B74B27248406347E350BF3320403ACFD8976C68484048DDCEBEF2082040B37A87DBA161484025E82FF488E11F40569C6A2DCC6048402FC214E5D2D81F405857056A315C48404565C39ACAB21F40F75AD07B63584840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('BAS-RHIN', '0106000020E610000001000000010300000001000000120000004565C39ACAB21F40F75AD07B6358484097E5EB32FC571F40AA29C93A1C5148404BC972124A0F1F408BE07F2BD9534840CE531D7233EC1E40035DFB027A534840378E588B4FC11E40B5DD04DF345548406D8C9DF0128C1E40386A85E97B594840AA9D616A4B9D1E40BAA0BE654E5D4840F1D58EE21C751E40DF88EE59D7664840ED478AC8B07A1E40BE9F1A2FDD6A4840C7D79E5912A01E40B56B425A636C484076374F75C8FD1E4060ADDA35216F48400A12DBDD03541F40477364E597734840F8A41309A69A1F40E010AAD4EC71484085D21742CECB1F4007793D98146F48409ED1562591DD1F40D87F9D9B366B4840433A3C84F1B31F40FEEF880AD5634840B7973446EB781F404580D3BB785B48404565C39ACAB21F40F75AD07B63584840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('HAUT-RHIN', '0106000020E6100000010000000103000000010000001900000082FE428F18ED1B40A47213B534014840B1FD648C0F131C40DC2C5E2C0C074840865AD3BCE3341C40D9B5BDDD920A48400C2252D32E561C403CF6B3588A10484028B517D1763C1C40BF9CD9AED01148403F912749D76C1C40C328081EDF184840ECA694D74A981C40570740DCD5214840B98AC56F0ACB1C408194D8B5BD274840B2DAFCBFEA181D40B265F9BA0C274840AF5C6F9BA9401D402975C93846204840309B00C3F2671D40A81DFE9AAC1F48407A39ECBE63E81D4052431B800D1A48406F2A52616CE11D40B2D5E59480144840DBDE6E490EC81D405A492BBEA11648402461DF4E22921D402C4487C091164840AD18AE0E80781D40C51C041DAD104840E355D636C5531D40C6C210397D0F4840998235CEA6431D40A3CA30EE06094840D177B7B244671D40DB166536C80648401D1D5723BB621D401230BABC39024840AAB706B64A501D40952C27A1F4F74740D5EAABAB02C51C407B4ACE893DF247409D6340F67A471C401BD5E940D6F34740CF68AB92C8EE1B404AEB6F09C0FD474082FE428F18ED1B40A47213B534014840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', True), ('HAUT-RHIN', '0106000020E6100000010000000103000000010000001F000000FB3E1C2444191E40F981AB3C81D44740126745D4445F1E4001E0D8B3E7CC4740B1A888D349561E40E770ADF6B0C947404CA4349BC7111E40079ACFB9DBC5474074CE4F711C081E40D4298F6E84BF4740FFE7305F5ED01D40D3156C239EBC4740740AF2B3918B1D4063F19BC24AB7474059130B7C45371D407C2766BD18B8474044DFDDCA12FD1C40B9196EC0E7B54740753E3C4B90F11C4093A7ACA6EBB74740B763EAAEECB21C40CD751A69A9B847400586AC6EF5AC1C40FD2D01F8A7BE47405DA8FC6B79851C40A400513063C04740307F85CC95911C40BCCE86FC33C347406C3F19E3C36C1C409109F83592C6474026E2ADF36F571C40B8E52329E9CB4740CDCAF6216F091C40244223D8B8CC47406A300DC347141C40D498107349D34740D06394675E2E1C402B8716D9CED54740950ED6FF391C1C402ECA6C9049DA47407D2079E750261C40661536035CDC4740A439B2F2CB801C40402FDCB930DA47409947FE60E0D91C40DCF29194F4D847400492B06F27011D4055185B0872DC4740AF93FAB2B4231D40180B43E4F4DB47405111A7936C251D40BF47FDF50AD7474069C36169E0471D4033E197FA79D547408D4127840E5A1D40E86C01A1F5CE47401C3F541A31A31D404435255987CB474001C287122D091E406901DA56B3D04740FB3E1C2444191E40F981AB3C81D44740', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('HAUT-RHIN', '0106000020E6100000010000000103000000010000001F0000007D2079E750261C40661536035CDC4740406A1327F70B1C409259BDC3EDDE47408CB96B09F9C01B40CD920035B5E247400186E5CFB7751B40399B8E006EE44740FC1D8A027D621B400FB4024356E9474037001B1021AE1B40639B5434D6EC47400953944BE3971B40328FFCC1C0F147409B75C6F7C5B51B404AD1CABDC0F44740E6913F1878AE1B406C0A647616F94740B60E0EF626C61B400F27309DD6FF474082FE428F18ED1B40A47213B534014840CF68AB92C8EE1B404AEB6F09C0FD47409D6340F67A471C401BD5E940D6F34740D5EAABAB02C51C407B4ACE893DF24740AAB706B64A501D40952C27A1F4F747401D1D5723BB621D401230BABC390248400C91D3D7F3751D40FCFCF7E0B5FF474081ECF5EE8FC71D40FCC22B499EFD4740F58079C894EF1D40336B2920EDF54740C89A9141EE521E40A79196CADBF54740861F9C4F1D3B1E4031410DDFC2F0474026529ACDE3401E406CB3B112F3EC47400AD80E46ECC31D40079B3A8F8AE9474068AED3484B951D40A296E65608EB474041B96DDFA33E1D40FFCEF6E80DEB47403485CE6BEC021D4082919735B1E44740C6C03A8E1FBA1C401FF7ADD689E1474011A8FE4124D31C40D047197101DE47409947FE60E0D91C40DCF29194F4D84740A439B2F2CB801C40402FDCB930DA47407D2079E750261C40661536035CDC4740', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('BAS-RHIN', '0106000020E6100000010000000103000000010000000600000021CA17B490C01E407558E1968F4C484092B442DA18271F40FB668163A34B484026FBE769C0F01E409DD9AED00749484029EACC3D24EC1E4009FD4CBD6E474840543A58FFE7D01E40A0C552245F47484021CA17B490C01E407558E1968F4C4840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('HAUT-RHIN', '0106000020E6100000010000000103000000010000000E00000069C36169E0471D4033E197FA79D547405111A7936C251D40BF47FDF50AD74740AF93FAB2B4231D40180B43E4F4DB47400492B06F27011D4055185B0872DC47409947FE60E0D91C40DCF29194F4D8474011A8FE4124D31C40D047197101DE4740ACADD85F762F1D40B4E55C8AABE04740DA8F149161851D40245E9ECE15E14740C156091687931D40C217265305E347403DB9A64066C71D4090F5D4EAABE147405A9BC6F65AE01D4045D8F0F44ADB47401D9430D3F6AF1D40B686527B11DB4740A0FF1EBC76691D40C30DF8FC30D8474069C36169E0471D4033E197FA79D54740', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('HAUT-RHIN', '0106000020E6100000010000000103000000010000001700000069C36169E0471D4033E197FA79D54740A0FF1EBC76691D40C30DF8FC30D847401D9430D3F6AF1D40B686527B11DB47405A9BC6F65AE01D4045D8F0F44ADB47403DB9A64066C71D4090F5D4EAABE14740C156091687931D40C217265305E34740DA8F149161851D40245E9ECE15E14740ACADD85F762F1D40B4E55C8AABE0474011A8FE4124D31C40D047197101DE4740C6C03A8E1FBA1C401FF7ADD689E147403485CE6BEC021D4082919735B1E4474041B96DDFA33E1D40FFCEF6E80DEB474068AED3484B951D40A296E65608EB47400AD80E46ECC31D40079B3A8F8AE9474026529ACDE3401E406CB3B112F3EC4740A7B1BD16F41E1E40AC1F9BE447E447408BA6B393C1311E40300F99F221DE4740B4041901150E1E402385B2F0F5D94740FB3E1C2444191E40F981AB3C81D4474001C287122D091E406901DA56B3D047401C3F541A31A31D404435255987CB47408D4127840E5A1D40E86C01A1F5CE474069C36169E0471D4033E197FA79D54740', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False), ('HAUT-RHIN', '0106000020E610000001000000010300000001000000120000000CCC0A45BA4F1E404E7B4ACE890F4840A054FB743C461E40E048A0C1A6044840EEE87FB9167D1E40603AADDBA0FC4740C89A9141EE521E40A79196CADBF54740F58079C894EF1D40336B2920EDF5474081ECF5EE8FC71D40FCC22B499EFD47400C91D3D7F3751D40FCFCF7E0B5FF47401D1D5723BB621D401230BABC39024840D177B7B244671D40DB166536C8064840998235CEA6431D40A3CA30EE06094840E355D636C5531D40C6C210397D0F4840AD18AE0E80781D40C51C041DAD1048402461DF4E22921D402C4487C091164840DBDE6E490EC81D405A492BBEA11648406F2A52616CE11D40B2D5E59480144840CAFCA36FD2141E404260E5D022134840FB7953910A131E4096CD1C925A1048400CCC0A45BA4F1E404E7B4ACE890F4840', '0101000020E61000009D2E8B89CDB71C400C2DA17197F74740', False)]